 Чат сообщества
Чат сообщества

| Модератор форума: Yuri_G |
| Сообщество uCoz Вебмастеру Раскрутка сайта Robots.txt (индексация сайта) |
| Robots.txt |
|
Нажмите на ссылку, чтобы перейти к ответу
Сообщение отредактировал webanet - Вторник, 27 Мар 2018, 20:08:42
|
|
Добрый день. При создании сайта возникла ситуация когда надо запретить индексацию всех страниц (index) но оставить главную... подскажите как правильно это Выполнить в robots.txt ?
|
|
worthyhero, вы должны понимать, что заочно составление файла занятие бессмысленное и иногда опасное для индексации. всегда нужно давать адрес сайта. если у вас все по умолчанию, то так
Disallow:/index |
|
webanet, Это запретит индексацию всех страниц кроме главной ?
|
|
Раша, проще говоря - с Disallow: /search не будут индексироваться все страницы поиска, тогда как с Disallow: /search/ - начальная страница его будет продолжать индексироваться. Собственно, по умолчанию так оно и есть:
Цитата agroraiders ( Disallow: /search/ Запрещает индексирование страницы результатов поиска и тегов Ex-ID: 179703 [11 Авг 2012]
 Сообщение отредактировал -SAM- - Пятница, 01 Фев 2019, 00:03:39
|
|
Добрый день!
Скажите пожалуйста, как правильно указать в файле robots.txt директивы Allow и Disallow Есть сайт 100minecraft.ru в котором нужно разрешить индексирование поиска на сайте по ключевым словам, но когда я указываю директиву Allow: /search в файле robots.txt, так поисковая система индексирует непонятные страницы К примеру в вебмастере показывает что проиндексированы страницы которых очень много и создает ненужные копии: /search/?q=%D0%A8%D0%B5%D0%B9%D0%B4%D0%B5%D1%80%D1%8B;t=0;p=4;md=dir%7Cload%7Csite%7Cstuff%7Cblog /search/?q=%D0%9C%D0%BE%D0%B4%D1%8B+%D0%B4%D0%BB%D1%8F+%D0%9C%D0%B0%D0%B9%D0%BD%D0%BA%D1%80%D0%B0%D1%84%D1%82;t=0;p=3;md=dir|load|stuff|site|blog Как прописать директивы чтобы индексировались только страницы /search/?q=%D0%A8%D0%B5%D0%B9%D0%B4%D0%B5%D1%80%D1%8B;t=0;p=4;md= и запретить индексацию dir%7Cload%7Csite%7Cstuff%7Cblog 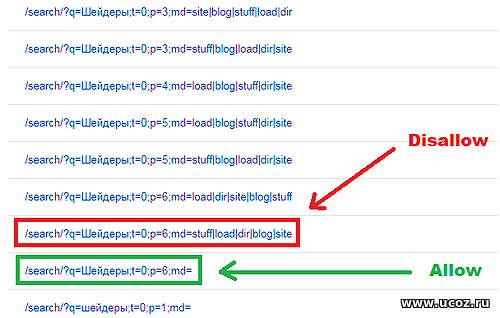 Добавлено (19 Фев 2019, 12:36:02) Цитата Prominecrafting ( и запретить индексацию dir%7Cload%7Csite%7Cstuff%7Cblog Allow: /search/ Disallow: /*/;md=stuff|load|dir|blog|site/ такие пойдут директивы? Добавлено (19 Фев 2019, 13:16:24) Прикрепления:
5763940.png
(57.0 Kb)
|
|
Привет, друзья. Подскажите пожалуйста, как в роботсе закрыть от индексирования страницу архива материалов что в новостях, что в блоге, что в статьях. Не хочу чтобы в индекс яндекса и гугля влетали списки материалов за 2010 - 02 - 33 например и всё такое. Ну чтобы мусора не было. Как таковое сотворить?
Здесь просто написано про то,где можно снять наличные с карты без процентов. Не заостряйте внимание.
|
|
Kurosava, это нужно делать не роботсом, а с помощью каноникала. в шаблон архива материалов модулей новости и блог в секцию head вставьте
Код <?if($PAGE_ID$=='day'||$PAGE_ID$=='month'||$PAGE_ID$=='year')?> <link rel="canonical" href="/" /> <meta name="robots" content="none"/> <?endif?> |
|
Цитата agroraiders ( Disallow: /*-0-0- Запрещает индексацию страниц добавления материалов, списков материалов пользователей, поиска по форуму, правил форума, добавления тем на форуме, различные фильтры (с дублями), страницы с редиректами на залитые на сервер файлы, страницы с редиректами на ссылки на скачивание с удаленного сервера Ссылки на скачивание там другого вида, что идут /load/0-0-1-$ID$-20 для удаленного (и соответственно /load/0-0-0-$ID$-20 с сервера) скачивания. Сейчас в Я.Вебмастере полно страниц вылезло, что ходит по этим ссылкам, а там редирект (у ссылки не было rel="nofollow" и она в robots.txt как раз и не запрещена). Еще добило тем, что полно страниц разных на фильтры-поиск на форуме, полечил так: Disallow: /forum/*-0-*0-1 Ну, а еще такое у себя был прописал Disallow: /*?ref=xranks - что оно, откуда берется, если кто знает - напишите, пожалуйста... или вообще стоит убрать Allow: /*?ref= ... на что-то повлияет, если на сайте такие ссылки не размещались? Ex-ID: 179703 [11 Авг 2012]
Сообщение отредактировал -SAM- - Понедельник, 06 Апр 2020, 06:53:07
|
|
Цитата Prominecrafting ( объясните нубу, потому что экспериментировать можно очень долго |
|
Здравствуйте! Как настроить robots, чтоб категории он индексировал только главную страницу? А остальные типа стр.2 стр.3 Запретил!
|
|
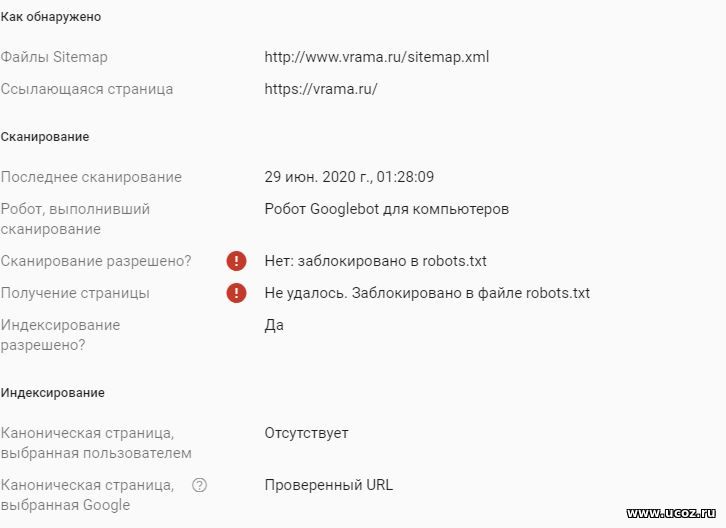
Доброго времени. Столкнулся с проблемой индексации гугл
Раньше User-agent: * стоял только такой, потом когда увидел что у гугла проблемы, добавил еще и эти User-agent: Googlebot User-agent: Yandex User-agent: Mail.Ru Как все таки лучше? Ссылка на сайт Прикрепления:
2623934.jpg
(40.0 Kb)
Сообщение отредактировал oregon - Вторник, 30 Июн 2020, 03:53:58
|













| |||
Будьте в курсе всех обновлений: подпишитесь на наш официальный Telegram-канал uCoz и задавайте вопросы в чате сообщества!